Relevance-based document models for Information Retrieval
Document models are used for information retrieval in order to compute the probability of a query being related to the document. The majority of document models are functions of the terms that appear within the document. This implies that a query is only relevant to a document if the query terms exist within the document, which is far from the truth.
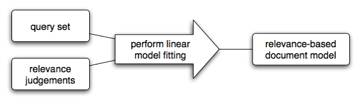
In our project, we have created a new form of document model called, a Relevance-based document model, which is built based on the relevance of each query to the document and not the words that appear within the document. Relevance-based document models are constructed using a set of queries and the associated relevance of the query to the document (shown in Fig. 6). This information allows us to construct a model that provides 100% precision results for the known queries and large improvements in precision over document content-based models for partially known queries. Since the relevance-based document models are based only on the query terms and their relevance to a document, the time required to build the models is very fast and the storage required to store the model is very compact.
To date, we have performed extensive experiments showing the behaviour of our relevance-based document models under difference circumstances. Our experiments have shown that by mixing the document content-based model with our relevance based document model, we are able to provide high precision results using low storage and fast query times.