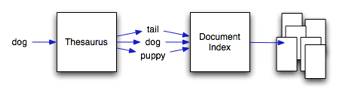
Automatic thesaurus construction using non-linear term relationships
Text based information retrieval systems retrieve documents based on the set of key terms provided to them. The documents returned are ranked according to the count of each query term, therefore if the query terms do not exist in the document it is not found. Latent semantic analysis (LSA) is a method of computing hidden topics within documents using linear algebra. By obtaining the relationships between each hidden topic and each term, we are able to compute which terms are similar by comparing the similarity of each of the terms topics. This hidden topic information allows the retrieval system to return documents that do not contain the query terms, but do contain terms that are similar to the query terms (shown in Fig. 5). The current linear algebraic techniques use the Euclidean distance as a similarity measure for vectors. Unfortunately, the Euclidean distance is not a useful metric for term or document similarity.
In our project, we are investigating several different metrics that are commonly within the field of information retrieval to replace the Euclidean distance measure. By doing so, we have generalised LSA to use a non-specific kernel function.
To date, we have investigated the BM25 kernel function and a standard TF-IDF kernel function. Both of these functions have been successfully using for information retrieval. Our initial results have shown an impressive increase in precision obtained by a retrieval system using our kernel LSA method over standard LSA.