Improving the quality of Web information retrieval using multi-resolution link analysis
The World Wide Web is the most important information source in modern society. The information within the Web is accessed through Web search engines such as Google and Yahoo. These search engines use a global popularity rank during the computation of their results, based on links from all of the pages on the Web. This global popularity rank used by Google is known as PageRank. Using these global popularity ranks biases the search results towards the globally popular Web pages. Our aim is to investigate the effect of a peer popularity rank where popularity is measured only through sites of a similar nature. We perform this task by observing the interaction between Web pages at a finer resolution (as shown in Fig. 1). We expect that using the peer popularity rank will allow search engines to locate Web pages that are more specific to the user needs rather than pages of general popularity. This will improve the quality of information that is delivered by Web search engines and provide organisation amongst the billions of existing Web pages.
We can illustrate our argument with this simple example. If we were to ask a group of people where to buy a toaster, they would direct us to one of the big stores like Myer; this is a popular shop but it is not a specialist in any area. On the other hand if we were to ask a group of people who know a lot about toasters, they would direct us to a specialist shop like "Joe's toaster emporium" where we would get specialist advice as to which toaster to choose. Please note that the Web was searched for a specialist toaster shop, but all that was returned was Amazon.com (the most popular general store on the Web). This result in itself shows that our research is essential.
To date, our research has lead us to analyse the effect of using Symmetric Non-negative Matrix Factorisation (SNMF) to discover multi-resolution Web communities. We have shown that by using this method, we could potentially provide a 50% increase in the precision of the retrieval results over Google's PageRank. Further research using SNMF must be performed to examine the relationships between the community ranks and the users' queries.
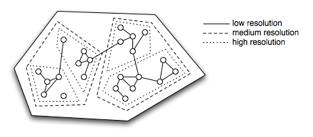
Fig. 1: A Web graph showing one community partition at the lowest resolution, two community partitions found at the medium resolution, and four community partitions found at a high resolution.
Discovering document model deficiencies for information retrieval
Text based information retrieval systems are built using document models. To analyse the retrieval precision of a model, a set of queries are provided to the model and the results are compared to the desired results. This type of analysis allows us to compare the precision of different retrieval models, but it does not provide us with any feedback on where the models could be improved. Currently there are no methods of analysis of text retrieval systems that are able to show where deficiencies lie within the document model. We aim to investigate methods of retrieval analysis that is able to reveal where specific document model deficiencies occur, using a given query and document set. Our analysis will allow information retrieval experiments to be more thorough and show why certain document models achieve a certain precision, thus allowing the document models to be adjusted and improved.
To date, we have developed a document model based entirely on a set of queries and the associated set of relevant documents. This model provides perfect precision for each of the known queries. We hope to use this relevance based model by comparing it to a given document model in order to identify differences (shown in Fig. 2). The differences will show where the deficiencies lie in the given document model. We have also shown that by combining this relevance based model with a standard document model, we are able to boost the precision of known queries while not loosing any precision for unknown queries.

Fig. 2: The document model deficiencies are found by comparing the document model to the oracle model.
Web page prefetching using temporal link analysis
Web searching should be as simple as providing the search engine with a query and having the search engine return a link to the desired Web page. Unfortunately, current Web search engines use text based queries and therefore require the user to provide keywords. Converting the users information need into a few key words is not a simple process. Due to this, Web search patterns involve the user visiting many Web pages that do not satisfy their information need, while interleaving this process with several visits to the Web search engine. Rather than the user actively searching for pages using key words, the search engine could provide pages to the user based on their Web usage patterns. By examining the users Web history, we will be able to compute the types of Web pages the user desires and hence provide search results to the user without the need for key words. This method of passive Web searching is called prefetching. Given that Google has had such success in using link analysis to provide useful retrieval results, we aim to investigate the utility of Web links to perform prefetching.
To date, we have successfully applied eigenvalue analysis to our temporal link graph (shown in Fig. 3) to obtain a measure of importance for each page. We will be examining the effect of using Hidden Markov models and their benefit over the eigenvalue analysis.
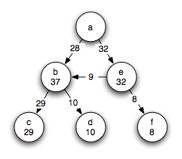
Fig. 3: A temporal link graph showing the time spent on each page (shown in each circle) and the portion of time from users that have followed each of the incoming links (shown on each of the directed edges).
Efficient and effective use of Language Models for Information Retrieval
Language models for text based information retrieval have become a de facto standard due to their simplicity and effectiveness. Recently, several language modelling techniques have been developed that assume a hidden distribution of topics within the set of documents. Such methods include Probabilistic Latent Semantic Analysis (PLSA) and Latent Dirichlet Allocation (LDA), where the former uses a multinomial distribution of topics, while the latter uses a Dirichlet prior. By using this notion of hidden topics, we are able to compute relationships from term to topic and hence term to term. Unfortunately, these language modelling methods produces large amounts of data and require lengthy periods of time to perform document retrieval.
For our project, we aim to investigate the data that these language modelling methods produce and hence develop methods of efficiently storing the data that is needed in order to maintain the high precision obtained by these systems. By reducing the data storage, we will also be able to speed up query times and hence provide a more useable topic based language model.
To date, we have shown that we can reduce the storage required by PLSA to 0.15% of its original storage while providing a statistically insignificant change in precision.
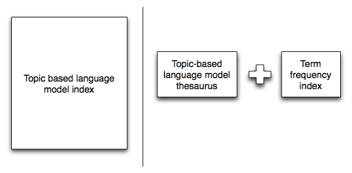
Fig. 4: PLSA large storage requirements when using an index can be drastically reduced by using a thesaurus and term frequency index in its place.
Automatic thesaurus construction using non-linear term relationships
Text based information retrieval systems retrieve documents based on the set of key terms provided to them. The documents returned are ranked according to the count of each query term, therefore if the query terms do not exist in the document it is not found. Latent semantic analysis (LSA) is a method of computing hidden topics within documents using linear algebra. By obtaining the relationships between each hidden topic and each term, we are able to compute which terms are similar by comparing the similarity of each of the terms topics. This hidden topic information allows the retrieval system to return documents that do not contain the query terms, but do contain terms that are similar to the query terms (shown in Fig. 5). The current linear algebraic techniques use the Euclidean distance as a similarity measure for vectors. Unfortunately, the Euclidean distance is not a useful metric for term or document similarity.
In our project, we are investigating several different metrics that are commonly within the field of information retrieval to replace the Euclidean distance measure. By doing so, we have generalised LSA to use a non-specific kernel function.
To date, we have investigated the BM25 kernel function and a standard TF-IDF kernel function. Both of these functions have been successfully using for information retrieval. Our initial results have shown an impressive increase in precision obtained by a retrieval system using our kernel LSA method over standard LSA.
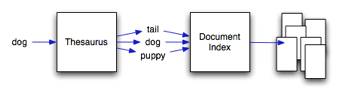
Fig. 5: The thesaurus is used to expand the users query into related terms to allow related documents that do not contain the query to be retrieved.
Relevance-based document models for Information Retrieval
Document models are used for information retrieval in order to compute the probability of a query being related to the document. The majority of document models are functions of the terms that appear within the document. This implies that a query is only relevant to a document if the query terms exist within the document, which is far from the truth.
In our project, we have created a new form of document model called, a Relevance-based document model, which is built based on the relevance of each query to the document and not the words that appear within the document. Relevance-based document models are constructed using a set of queries and the associated relevance of the query to the document (shown in Fig. 6). This information allows us to construct a model that provides 100% precision results for the known queries and large improvements in precision over document content-based models for partially known queries. Since the relevance-based document models are based only on the query terms and their relevance to a document, the time required to build the models is very fast and the storage required to store the model is very compact.
To date, we have performed extensive experiments showing the behaviour of our relevance-based document models under difference circumstances. Our experiments have shown that by mixing the document content-based model with our relevance based document model, we are able to provide high precision results using low storage and fast query times.
Fig. 6: The relevance-based document model is built using a linear model of the query set and relevance judgements.
Approximate clustering of very large scale data
Many machine learning, data mining and statistical analysis tasks are used to identify properties of data, or to build models of sampled data. Unfortunately, these analytical methods are computationally expensive; their computational resource use being a function of the dimensionality and sample count of the data being analysed. Recent advances is data acquisition (such as genetic sequencing) have allowed us to capture very large amounts of data (of the order of terabytes) for analysis and modelling. The complexity of current machine learning and data mining methods makes them infeasible to be directly applied to such large scale data.
In this project, we will examine methods of computing approximate clusterings of very large scale data in an efficient and scalable manner. By obtaining approximate clusters, we will be able to partition large data sets into smaller, more manageable, independent sets in which we can easily apply machine learning and data mining analysis.
To date, we have developed a scalable version of coVAT (Visual Assessment of Co-Cluster Tendency) that provides a graphical mapping of the co-clusters within a data set. Using this mapping, the user is able to identify the number of co-clusters within the data set and where to partition the data to obtain approximate independent partitions.

Fig. 7: A coVAT image showing the co-clusters inherent in a very large scale data set.